一、项目介绍
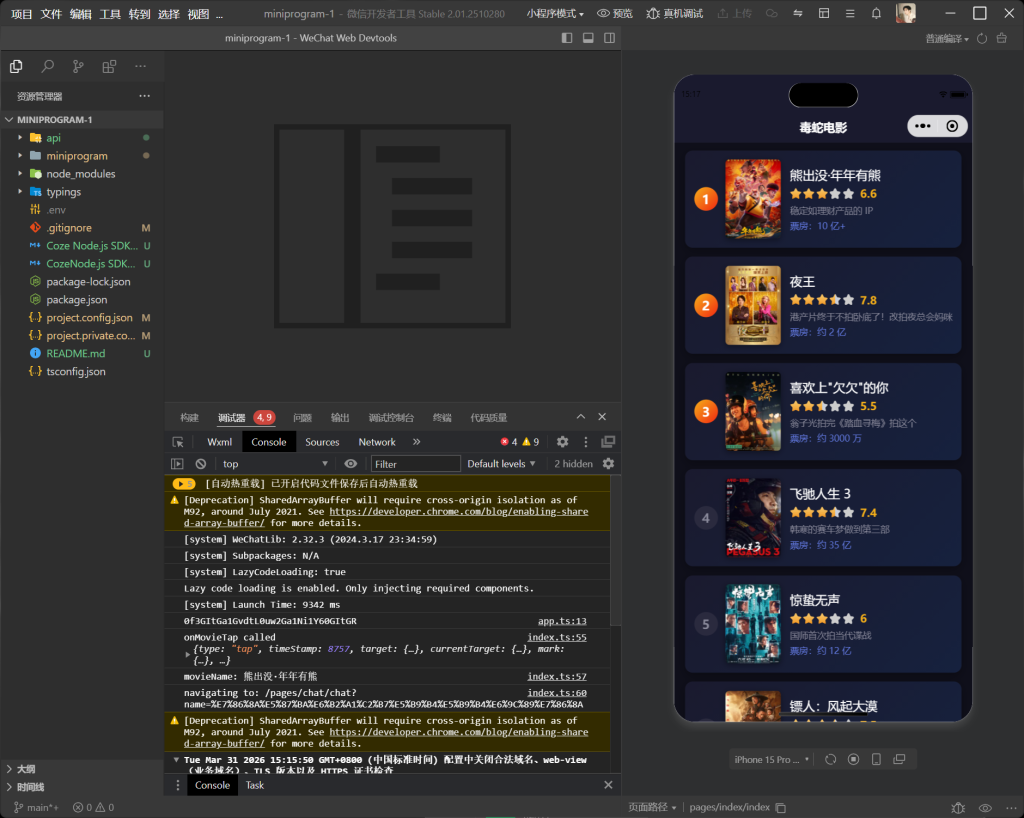
通过DeepSeek + Coze作为后端,来评价今年春节档的电影。
程序首页会展示春节档的电影评分和票房,电影详情页面会请求Coze的后端API,实现AI毒舌评论春节档的效果。并且你还可以通过聊天对话框和AI对话,了解这一部电影的更多细节。
二、项目流程
- 需要数据,通过python 爬取热门电影评论数据
- 1.需要数据,用python去爬取一些电影评论数据
- 2.将评论数据给deepseek总结毒蛇评论
- 3.使用coze+deepseek作为AI后端服务
- 4.使用vs开发微信小程序
python爬虫代码
import requests
import time
import random
import json
import re
from bs4 import BeautifulSoup
from typing import List, Dict
class DoubanHotComments:
"""豆瓣电影热门短评爬虫"""
def __init__(self, movie_id: str, max_page: int = 19):
"""
初始化爬虫
Args:
movie_id: 豆瓣电影 ID(从电影 URL 中获取,如 https://movie.douban.com/subject/1292052/ 中的 1292052)
max_page: 最大爬取页数,默认 19 页(每页 20 条评论)
"""
self.movie_id = movie_id
self.max_page = max_page
self.base_url = f"https://movie.douban.com/subject/{movie_id}/comments"
# 请求头配置 - 请填写你的 Cookie
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": f"https://movie.douban.com/subject/{movie_id}/",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": 'bid=F1Y2CoLN6pg; _pk_id.100001.4cf6=38f6f33056d6077f.1774755922.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1768631440.1774755923.1774755923.1774755923.1; __utmc=30149280; __utmz=30149280.1774755923.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); ll="118104"; __utma=223695111.1761289315.1774755926.1774755926.1774755926.1; __utmb=223695111.0.10.1774755926; __utmc=223695111; __utmz=223695111.1774755926.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _vwo_uuid_v2=DF10EFB86C3F78959571C9B60480F24F7|d4641f2ce9f2eda2ce522e44236dc345; __yadk_uid=u7YVitQxGAlpbHWa9uEjwKiFwF3qgzfi; dbcl2="294408059:iGFBFmLhMjg"; ck=Gf4c; frodotk_db="9db850ac5fb597d6d928f2051f20c782"; push_noty_num=0; push_doumail_num=0; __utmt=1; __utmv=30149280.29440; __utmb=30149280.11.10.1774755923',
}
self.session = requests.Session()
self.comments_data: List[Dict] = []
self.movie_name = "" # 电影名字
def get_movie_name(self) -> str:
"""
获取电影名字
Returns:
电影名字
"""
# 如果已经获取过,直接返回
if self.movie_name:
return self.movie_name
try:
response = self.session.get(
f"https://movie.douban.com/subject/{self.movie_id}/",
headers=self.headers,
timeout=10
)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# 获取电影标题
title_elem = soup.find("span", property="v:itemreviewed")
if title_elem:
self.movie_name = title_elem.text.strip()
# 清理文件名中不允许的字符
self.movie_name = re.sub(r'[\\/:*?"<>|]', '', self.movie_name)
print(f"获取到电影名字:{self.movie_name}")
return self.movie_name
else:
print("未找到电影标题元素")
else:
print(f"获取电影信息失败,状态码:{response.status_code}")
except Exception as e:
print(f"获取电影名字失败:{e}")
self.movie_name = f"movie_{self.movie_id}"
print(f"使用默认电影名字:{self.movie_name}")
return self.movie_name
def get_json_filename(self) -> str:
"""
获取 JSON 文件名(使用电影名字命名)
Returns:
文件名
"""
# 如果还没有电影名字,先获取
if not self.movie_name:
self.get_movie_name()
# 使用电影名字命名,如果获取失败则使用电影 ID
if self.movie_name:
return f"{self.movie_name}.json"
else:
return f"movie_{self.movie_id}.json"
def get_comments(self, page: int = 1) -> List[Dict]:
"""
获取指定页的短评
Args:
page: 页码,从 1 开始
Returns:
评论列表
"""
params = {"start": (page - 1) * 20, "type": "T", "limit": 20, "status": "P"}
try:
response = self.session.get(
self.base_url,
headers=self.headers,
params=params,
timeout=10
)
if response.status_code == 200:
return self.parse_html(response.text)
elif response.status_code == 403:
print(f"第{page}页:访问被拒绝,可能是 Cookie 失效或 IP 被限制")
return []
else:
print(f"第{page}页:请求失败,状态码 {response.status_code}")
return []
except requests.RequestException as e:
print(f"第{page}页:请求异常 - {e}")
return []
def parse_html(self, html: str) -> List[Dict]:
"""
解析 HTML 内容,提取评论数据
Args:
html: 网页 HTML 内容
Returns:
评论列表
"""
soup = BeautifulSoup(html, "html.parser")
comments = []
# 查找所有评论项
comment_items = soup.find_all("div", class_="comment-item")
for item in comment_items:
try:
# 用户名
user_elem = item.find("span", class_="comment-info")
username = user_elem.find("a").text.strip() if user_elem and user_elem.find("a") else "匿名用户"
# 用户主页链接
user_link = user_elem.find("a")["href"] if user_elem and user_elem.find("a") else ""
# 评论内容
content_elem = item.find("p", class_="comment-content")
content = content_elem.text.strip() if content_elem else ""
# 评分
rating_elem = item.find("span", class_="rating")
rating = ""
if rating_elem:
rating_class = rating_elem.get("class", [])
for cls in rating_class:
if cls.startswith("rating"):
rating = cls.replace("rating", "")
break
# 有用数
useful_elem = item.find("span", class_="votes")
useful_count = useful_elem.text.strip() if useful_elem else "0"
# 评论时间
time_elem = item.find("span", class_="comment-time")
comment_time = time_elem.text.strip() if time_elem else ""
comments.append({
"username": username,
"user_link": user_link,
"content": content,
"rating": rating,
"useful_count": useful_count,
"time": comment_time
})
except Exception as e:
print(f"解析评论时出错:{e}")
continue
return comments
def crawl(self, delay: float = 2.0) -> List[Dict]:
"""
执行爬取任务
Args:
delay: 请求间隔时间(秒),防止被反爬
Returns:
所有评论数据
"""
print(f"开始爬取电影 ID: {self.movie_id}")
print(f"计划爬取页数:{self.max_page}")
print(f"目标 URL: {self.base_url}")
print("-" * 50)
# 检查 Cookie 是否填写
if not self.headers["Cookie"]:
print("警告:Cookie 未填写!请在代码中填写 Cookie 后重试")
print("获取 Cookie 方法:")
print("1. 打开豆瓣电影网页,按 F12 打开开发者工具")
print("2. 切换到 Network 标签,刷新页面")
print("3. 点击任意请求,在 Request Headers 中找到 Cookie")
print("4. 复制 Cookie 值粘贴到代码中的 Cookie 字段")
print("-" * 50)
return []
# 重新创建 session,清除可能的缓存
self.session = requests.Session()
all_comments = []
for page in range(1, self.max_page + 1):
print(f"正在爬取第 {page} 页...")
page_comments = self.get_comments(page)
if page_comments:
all_comments.extend(page_comments)
print(f" 成功获取 {len(page_comments)} 条评论")
else:
print(f" 本页没有获取到评论")
# 如果连续几页都没有数据,可能是触发了反爬
if page > 3:
print(" 提示:可能是 Cookie 失效或 IP 被限制,建议检查后重试")
# 随机延迟,防止被封
if page < self.max_page:
sleep_time = delay + random.uniform(0.5, 1.5)
time.sleep(sleep_time)
self.comments_data = all_comments
print("-" * 50)
print(f"爬取完成!共获取 {len(all_comments)} 条评论")
return all_comments
def save_to_json(self, append: bool = True) -> str:
"""
将评论数据保存为 JSON 文件(按电影名字命名)
Args:
append: 是否追加到现有文件,默认 True
Returns:
保存的文件路径
"""
# 先确保获取了电影名字
if not self.movie_name:
self.get_movie_name()
filename = f"{self.movie_name}.json"
print(f"电影名称:{self.movie_name}")
print(f"保存文件名:{filename}")
print(f"电影 ID: {self.movie_id}")
if not self.comments_data:
print("没有数据可保存")
return ""
# 如果追加模式且文件存在,读取已有数据
all_comments = []
if append:
try:
with open(filename, "r", encoding="utf-8") as f:
all_comments = json.load(f)
print(f"读取到已有 {len(all_comments)} 条评论")
except FileNotFoundError:
all_comments = []
except json.JSONDecodeError:
all_comments = []
# 追加新评论(去重)
existing_ids = set()
for comment in all_comments:
if "unique_id" in comment:
existing_ids.add(comment["unique_id"])
new_count = 0
for comment in self.comments_data:
# 生成唯一 ID(用户 + 时间 + 内容前缀)
unique_id = f"{comment['username']}_{comment['time']}_{comment['content'][:20]}"
if unique_id not in existing_ids:
comment["unique_id"] = unique_id
all_comments.append(comment)
new_count += 1
try:
with open(filename, "w", encoding="utf-8") as f:
json.dump(all_comments, f, ensure_ascii=False, indent=2)
print(f"数据已保存到:{filename}")
print(f"新增 {new_count} 条评论,总计 {len(all_comments)} 条")
return filename
except Exception as e:
print(f"保存文件时出错:{e}")
return ""
def main():
"""主函数"""
# 电影 ID 示例:
# 肖申克的救赎:1292052
# 霸王别姬:1293544
# 这个杀手不太冷:1295644
movie_id = input("请输入豆瓣电影 ID(或按回车使用示例 ID 1292052):").strip()
if not movie_id:
movie_id = "1292052" # 默认肖申克的救赎
# 创建爬虫实例
crawler = DoubanHotComments(movie_id=movie_id, max_page=19)
# 执行爬取
comments = crawler.crawl(delay=2.0)
if comments:
# 保存为 JSON 格式(文件名为 movie_{电影 ID}.json,自动追加)
crawler.save_to_json()
# 显示前 5 条评论预览
print("\n前 5 条评论预览:")
print("-" * 50)
for i, comment in enumerate(comments[:5], 1):
print(f"{i}. [{comment['rating']}星] {comment['username']}: {comment['content'][:50]}...")
if __name__ == "__main__":
main()
技术栈:
前端:原生小程序代码
后端:python爬虫+Node.js=Express.js
智能体:coze智能体、coze知识库
三、项目过程:
1.问题:
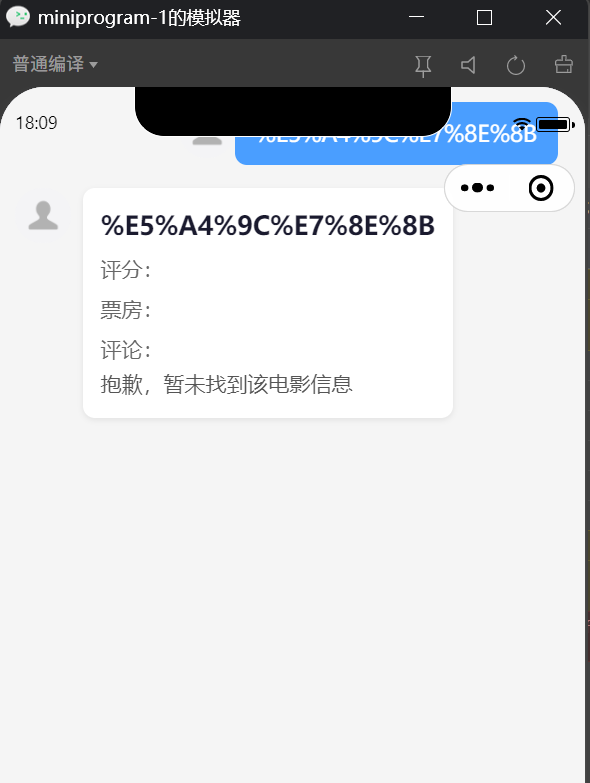
卡片容器没有做内边距约束,内容直接贴边,没有安全距离。
chat页面,没有给手机顶部状态栏留空隙,直接顶到头。
没给顶部加margin/padding。
没有文字显示,乱码原因是:后端返回的流式响应包含了 Coze API 的原始 JSON 数据(含内部调试信息、prompt 等),而前端的解析逻辑太简单,直接拼接了所有 chunk.data.content,导致把 JSON 转义字符串也当作内容显示了。
问题分析:
前端解析逻辑过于简单 – 只是简单地拼接 chunk.data.content 或 chunk.content,没有正确过滤 Coze 的内部消息类型
后端返回的 chunk 格式不统一 – 有时是 {event:..., data:...},有时是 {msg_type:..., data:...},有时直接是内容字符串
图片无法解析,图片是通过 <rich-text> 渲染的,但小程序的 rich-text 对图片链接有要求:
- 必须配置合法域名 –
img1.doubanio.com需要在小程序后台配置 - 或者使用
web-view方式 – 但更简单的是把图片下载下来用<image>组件显示
解决方案:修改 parseMarkdown 函数,提取图片并单独渲染
但这比较复杂。更简单的方法是:直接在 WXML 中解析 Markdown 图片语法,或者配置不校验域名(开发环境)。
最简单的方法是在开发工具中关闭域名校验:
chat.ts | 修改 parseMarkdown 函数,提取图片 URL 到数组,不再直接生成 <img> 标签 |
chat.ts | 更新 handleStreamResponse 使用新的返回值结构 { html, images } |
chat.wxml | 添加 <image> 组件循环渲染 item.images 数组 |
chat.less | 添加 .markdown-image 样式 |
豆瓣进行了反爬,图片无法加载。需要去coze重新添加照片非豆瓣
四、项目问题解答
- 为什么选择流式响应而不是普通请求?
流式响应的优势:
对比项 普通请求 流式响应
首字延迟 需等待完整响应 即时显示(~100ms)
用户体验 长时间等待无反馈 打字机效果,感知更快
超时风险 长文本易超时 分块传输,降低超时概率
内存占用 一次性加载全部内容 逐块处理,内存更优
流式响应的挑战:
// 小程序流式处理的特殊问题:
// 1. wx.request 对流式支持有限,需要 responseType: ‘arraybuffer’
// 2. 需要手动拼接 chunk,处理粘包/拆包
// 3. Markdown 解析需要等完整内容或增量解析
// 4. 错误处理更复杂(中途断开需恢复)
为什么本项目选择流式:
AI 生成内容较慢,流式可提升感知速度
Coze API 原生支持 SSE 流式输出
符合主流 AI 产品体验(如 ChatGPT)
- 你的前端和后端通信协议是如何设计的?
为什么后端返回的 chunk 结构是 {event:…, data:…} 这样的格式?
如果 Coze API 的响应格式变化,你的代码如何应对?
2. 前后端通信协议设计
当前后端返回格式:
// api/index.js
res.write(JSON.stringify(chunk) + '\n');
// chunk 结构(来自 Coze SDK)
{
event: "conversation.message.delta",
data: {
id: "...",
content: "实际内容"
}
}
为什么这样设计:
- 直接透传 Coze SDK 的 chunk 结构,减少后端处理
event字段用于区分消息类型(delta/completed/error)data字段包含实际业务数据
如何应对格式变化:
// 当前代码的问题:硬编码了 event 类型判断
if (chunk.event === 'conversation.message.delta') { ... }
// 更好的设计:协议抽象层
interface ChatChunk {
type: 'content' | 'complete' | 'error';
payload: any;
}
function parseChunk(raw: any): ChatChunk {
// 统一转换不同来源的 chunk 格式
// 这样 Coze 格式变化时只需修改这里
}
- 消息列表很长时,如何优化滚动性能?
当前 scroll-view 的 scroll-into-view 有什么性能隐患?
如何实现虚拟列表优化?
当前实现的问题:
…
性能隐患:
scroll-into-view 每次触发都需查询 DOM
消息超过 100 条后渲染明显变慢
所有消息节点常驻内存
虚拟列表实现方案:
// 只渲染可视区域内的消息
data: {
visibleMessages: [], // 只包含可视区域的消息
containerHeight: 0,
itemHeight: 100, // 预估每条消息高度
startIndex: 0,
endIndex: 10
}
onScroll(e) {
const scrollTop = e.detail.scrollTop;
const startIndex = Math.floor(scrollTop / this.data.itemHeight);
const endIndex = startIndex + this.data.visibleCount;
this.setData({
startIndex,
visibleMessages: messages.slice(startIndex, endIndex),
offsetY: startIndex * this.data.itemHeight
});
}
…
- 图片加载失败时,你的处理策略是什么?
除了过滤豆瓣图片,还有什么更好的方案?
如何实现图片的降级/占位图机制?
当前方案的问题:
// 简单过滤豆瓣图片
if (!src.includes(‘doubanio.com’)) {
images.push(src);
}
更好的方案:
方案 A:占位图 + 错误处理

onImageError(e) {
// 加载失败时替换为占位图
const index = e.currentTarget.dataset.index;
this.setData({
[messages[${index}].imageError]: true
});
}

方案 B:后端代理图片
// api/proxy-image.js
app.get(‘/api/proxy-image’, async (req, res) => {
const url = req.query.url;
const response = await fetch(url);
const buffer = await response.arrayBuffer();
res.setHeader(‘Content-Type’, ‘image/jpeg’);
res.send(Buffer.from(buffer));
});
方案 C:获取电影海报替代
// 从本地数据库获取海报
async function getMoviePoster(movieName) {
const movie = movieData.find(m => m.name === movieName);
return movie?.poster || ‘/images/default-poster.png’;
}
- 网络请求超时或失败时,你的错误处理机制是什么?
如果后端服务器宕机,前端如何应对?
是否需要实现重试机制?如何设计?
5. 网络请求超时/失败处理
当前代码:
fail(err) {
console.error('Request failed:', err);
that.setData({ loading: false });
wx.showToast({
title: '请求失败,请重试',
icon: 'none'
});
}
改进方案:
class ChatService {
private maxRetries = 3;
private retryDelay = 1000;
async sendMessage(message: string, retryCount = 0) {
try {
return await this.doRequest(message);
} catch (err) {
if (retryCount < this.maxRetries) {
// 指数退避重试
await this.sleep(this.retryDelay * Math.pow(2, retryCount));
return this.sendMessage(message, retryCount + 1);
}
// 重试失败,提供降级方案
this.showFallbackOptions();
throw err;
}
}
private showFallbackOptions() {
wx.showModal({
title: '服务暂时不可用',
content: '是否切换到离线模式?',
confirmText: '离线模式',
success: (res) => {
if (res.confirm) {
this.useLocalData();
}
}
});
}
}
后端宕机应对:
- 配置云函数作为备用后端
- 本地缓存常用电影数据
- 提供离线问答能力
6. 流式响应解析失败时,如何定位问题?
- 当前代码的调试日志是否足够?
- 如何设计一个更完善的错误上报系统?
当前调试日志:
console.log('=== Stream Lines Count ===', lines.length);
console.log('=== Full Content ===', fullContent);
完善的日志系统:
class StreamParser {
parse(streamData: string) {
const logs: LogEntry[] = [];
const startTime = Date.now();
try {
const lines = streamData.split('\n').filter(l => l.trim());
logs.push({ type: 'info', message: `Received ${lines.length} lines` });
lines.forEach((line, idx) => {
const chunk = JSON.parse(line);
logs.push({
type: 'chunk',
index: idx,
event: chunk.event,
contentLength: chunk.data?.content?.length || 0,
timestamp: Date.now() - startTime
});
});
this.reportLogs(logs);
} catch (err) {
logs.push({
type: 'error',
message: err.message,
rawLine: line,
timestamp: Date.now() - startTime
});
this.reportLogs(logs);
}
}
private reportLogs(logs: LogEntry[]) {
// 发送到日志服务器
wx.request({
url: 'https://your-server.com/api/log',
method: 'POST',
data: { logs, sessionId: this.sessionId }
});
}
}7. 你的 .env 文件包含敏感 API Token,如何保护?
- 如何防止 Token 被泄露到前端?
- 后端如何验证请求来源?
8. 小程序域名校验问题,生产环境如何解决?
- 为什么豆瓣图片在开发环境可以关闭校验?
- 上线后如何配置合法域名?
9. parseMarkdown 函数的正则表达式有什么潜在问题?
- 如果 Markdown 语法更复杂(如嵌套、转义),当前正则会失效吗?
- 是否会考虑使用成熟的 Markdown 解析库?
10. 如果要支持多轮对话(上下文),如何设计?
- 当前的
conversation_id是如何管理的? - 如何保存和加载历史聊天记录?
7. API Token 保护
当前架构的安全性分析:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 小程序 │────▶│ 后端服务 │────▶│ Coze API │
│ (前端) │ │ (Node.js) │ │ (云端) │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌───────────┐
│ .env │
│ COZE_TOKEN│
└───────────┘
Token 保护得好吗? ✅ 是的
- Token 只存储在后端
.env文件 - 前端只能访问
localhost:3000,无法直接访问 Coze - Token 不会暴露给客户端
进一步增强:
// 后端添加请求验证
const SECRET_KEY = process.env.APP_SECRET;
app.post('/api/chat/stream', (req, res, next) => {
const signature = req.headers['x-request-signature'];
const expected = crypto
.createHmac('sha256', SECRET_KEY)
.update(JSON.stringify(req.body))
.digest('hex');
if (signature !== expected) {
return res.status(401).json({ error: 'Unauthorized' });
}
next();
});
// 前端添加签名
const signature = crypto
.createHmac('sha256', APP_SECRET)
.update(JSON.stringify({ message, bot_id }))
.digest('hex');
wx.request({
header: {
'x-request-signature': signature
}
});
8. 小程序域名校验
开发环境可关闭校验的原因:
- 微信开发者工具提供”不校验合法域名”选项
- 仅用于开发调试,方便本地测试
生产环境必须配置:
// 微信公众平台配置
request 合法域名:
- https://your-domain.com
uploadFile 合法域名:
- https://your-domain.com
downloadFile 合法域名:
- https://img.your-cdn.com
- https://*.doubanio.com (如需要豆瓣图片)
豆瓣图片域名问题:
- 豆瓣不允许直接外链图片(返回 418)
- 即使配置了域名也可能无法访问
- 解决方案:使用自己的 CDN 代理或图床
五、代码质量与扩展
9. Markdown 正则解析的局限性
当前实现的问题:
// 问题 1:无法处理嵌套
// 输入:**加粗和*斜体*混合**
// 输出:错误解析
// 问题 2:无法处理转义
// 输入:\[不是链接\](url)
// 输出:仍会被匹配
// 问题 3:性能问题
// 长文本多次 replace 遍历效率低
使用成熟库的优势:
// 使用 marked 或 markdown-it
import markdownIt from 'markdown-it';
const md = markdownIt({
html: false, // 禁用 HTML 标签(安全)
linkify: true, // 自动转换 URL 为链接
typographer: true // 优化标点符号
});
const html = md.render(markdownText);
为什么项目没使用库:
- 小程序包大小限制(2MB)
- 本项目的 Markdown 用法简单
- 自定义解析可精确控制输出
建议: 如果项目扩大,应该引入成熟库
10. 多轮对话上下文设计
当前实现:
data: {
conversationId: '' // 来自 Coze API
}
sendToCoze(message: string) {
wx.request({
data: {
conversation_id: this.data.conversationId
}
});
}
问题:
conversationId没有持久化,刷新页面丢失- 没有本地历史消息存储
- 无法查看之前的对话
完整的多轮对话方案:
// 1. 会话管理
class ConversationManager {
private storageKey = 'chat_conversations';
// 创建新会话
createConversation(movieName: string): Conversation {
const conv = {
id: generateUUID(),
movieName,
createdAt: Date.now(),
messages: []
};
this.save(conv);
return conv;
}
// 加载历史会话
loadHistory(movieName: string): Conversation[] {
const all = wx.getStorageSync(this.storageKey) || [];
return all.filter(c => c.movieName === movieName);
}
// 添加消息
addMessage(convId: string, message: Message) {
const conv = this.load(convId);
conv.messages.push(message);
this.save(conv);
}
private save(conv: Conversation) {
// 存储到本地,考虑大小限制
const all = wx.getStorageSync(this.storageKey) || [];
// 只保留最近 50 条消息
conv.messages = conv.messages.slice(-50);
wx.setStorageSync(this.storageKey, all);
}
}
// 2. UI 支持
data: {
conversations: [], // 会话列表
currentConvId: '', // 当前会话
showHistory: false // 是否显示历史
}
<!-- 会话切换 UI -->
<view class="conversation-switcher" bind:tap="toggleHistory">
<text>{{currentConversation?.movieName || '新对话'}}</text>
</view>
<view wx:if="{{showHistory}}" class="history-panel">
<block wx:for="{{conversations}}">
<view bind:tap="switchConversation" data-id="{{item.id}}">
{{item.movieName}} - {{formatTime(item.createdAt)}}
</view>
</block>
</view>