一、这个项目做了什么
先用一句话概括:
VibVib 是一个基于 Next.js App Router 构建的 AI 视频生成 Web 原型,支持用户注册登录,并通过 Kie.ai 接入多个文生视频模型,完成从 prompt 输入到视频结果返回的一整条链路。
当前版本主要包含四部分:
- 产品落地页
- 登录与注册系统
- 受保护的生成工作台
- Kie.ai 文生视频模型接入
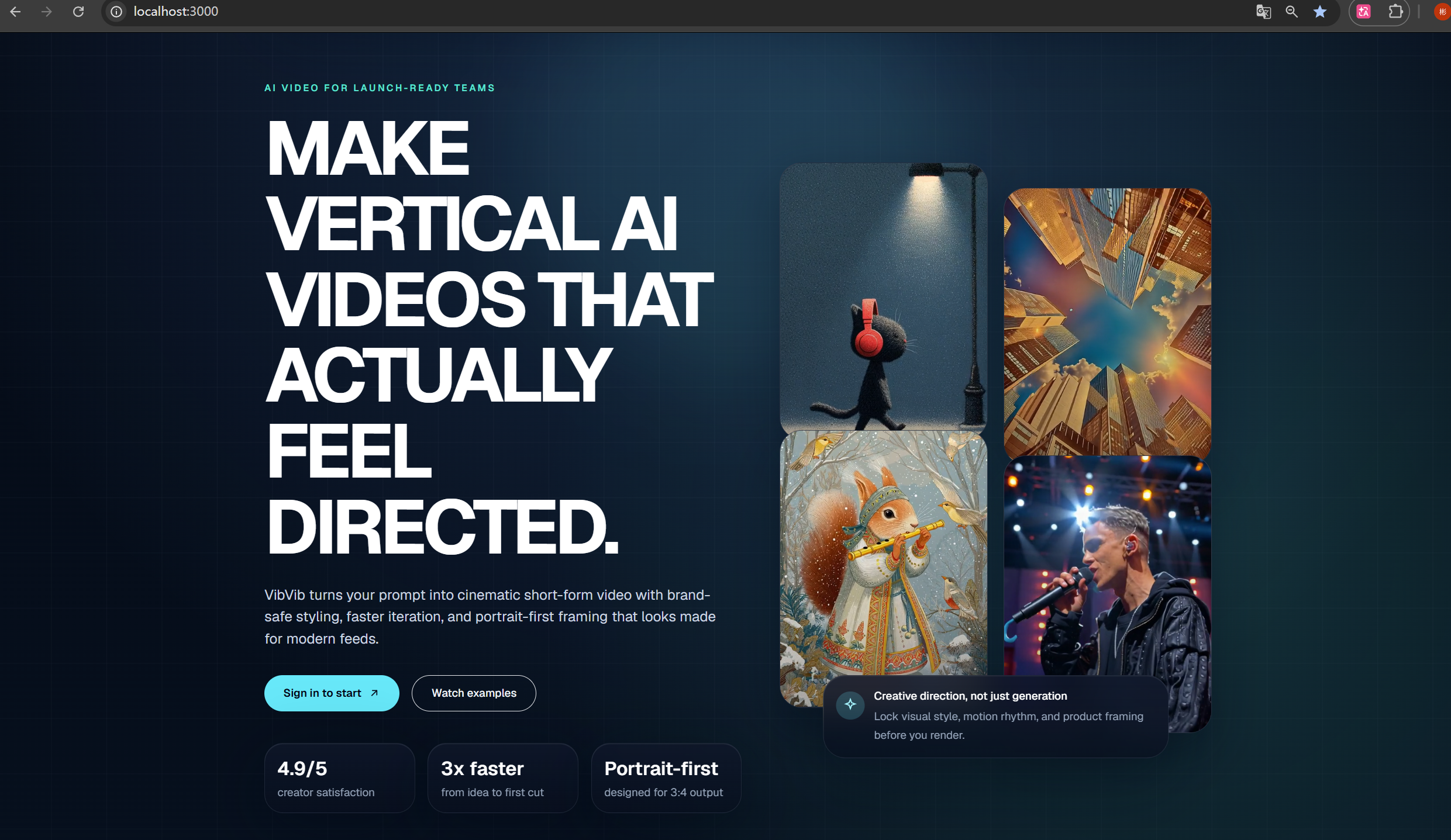
首页部分不再是默认模板,而是一个完整的 AI 产品 Landing Page。我围绕 public/video/ 中现有的 3:4 视频素材设计了页面结构,让它更像一个真实可展示的产品官网,而不是一个简单的开发测试页。
登录和注册页也统一到了同一套视觉体系下,保持品牌风格一致。用户登录后进入 /protected,这里是整个项目最核心的部分,一个可以实际发起 AI 视频生成任务的工作台。
二、为什么做这个项目
做这个项目的直接原因很简单:我不想只停留在“能调通 API”的阶段,而是想把“模型能力接入”真正放进一个产品雏形里。
很多 AI 应用教程只做到下面这一步:
- 写一个输入框
- 把 prompt 发给第三方接口
- 在控制台打印返回结果
这当然能证明接口打通了,但它离“产品”还差得很远。
我更感兴趣的问题是:
- 如果这是一个真正给用户用的 AI 视频工具,前端长什么样?
- 用户如何选择不同模型?
- 不同模型参数不一样,该怎么抽象?
- 文生视频不是同步返回结果,异步任务流怎么设计?
- 如何把模型能力包装进一个清晰、可扩展的 Web 应用里?
所以 VibVib 更像是一次“从能力验证走向产品原型”的练习。
三、技术栈
这个项目当前使用的技术栈比较直接,但组合起来很适合做这种 AI SaaS 原型:
- Next.js 14:App Router 架构,统一处理页面和 API
- React 18
- NextAuth:处理邮箱密码登录
- Postgres + Drizzle ORM:用户信息存储
- bcrypt-ts:密码哈希
- Tailwind CSS:快速搭建统一视觉
- Kie.ai:提供文生视频模型能力
整体上我没有追求过度复杂的架构,而是优先保证这几个目标:
- 页面结构清晰
- 前后端职责分离
- 模型参数易于扩展
- 具备真实产品的基本体验
四、首页:从模板到产品落地页
一开始这个项目只是一个默认的登录模板页面,视觉和内容都非常通用。后来我把首页重写成了一个更像 AI 产品官网的落地页。
我在设计时重点做了几件事:
- 用 3:4 视频素材作为视觉核心
项目里本来就有一组 public/video/ 下的视频素材,而且比例很适合短视频内容展示。我没有把它们简单平铺,而是做成了更有层次的展示墙和视频卡片,让页面更像一个真正服务“视频生成”的产品。 - 统一品牌语气
我把产品命名为 VibVib,并围绕“AI video for launch-ready teams”这条叙事线组织首页文案,让落地页更像一个面向创作者和营销团队的工具,而不是一个技术实验页面。 - 强化产品感
除了 Hero 区,我还补了 Features、Showcase、Pricing、FAQ 和 Final CTA,让结构更接近成熟 SaaS 落地页。 - 登录态联动
首页 CTA 会根据用户是否登录,决定跳转到 /login 还是 /protected,这样入口逻辑就统一了。
这个部分让我最满意的一点是:首页已经不再像“模板首页”,而是真的有了一点产品展示的味道。
五、登录注册:不只是能用,还要风格统一
AI 产品很容易出现一个常见问题:首页做得很漂亮,但登录页还是默认模板,用户一点击进去,整体体验马上断层。
所以我把 /login 和 /register 也统一改成了和首页一致的设计语言:
- 同样的深色渐变背景
- 同样的玻璃卡片风格
- 同样的品牌色和排版节奏
- 同样的 CTA 风格
技术上这部分并不复杂,核心还是基于 NextAuth 的 credentials 方案实现邮箱密码登录,但因为视觉统一做得更完整,所以整个体验更像一套产品,而不是几个拼起来的独立页面。
六、受保护工作台:这个项目最核心的部分
真正有意思的地方在 /protected。
这里不再只是一个简单的 “You are logged in as …” 页面,而是被我改造成了一个文生视频控制台,也可以理解成一个最小可用的 AI 视频生成工作台。
用户登录之后,可以在这里完成完整的一次生成流程:
- 选择模型
- 填写 prompt
- 调整模型对应参数
- 提交生成任务
- 查看任务状态
- 成功后预览返回的视频结果
这个页面本质上就是产品的“工作区”,它把原本零散的模型能力封装成了一个更接近真实使用场景的交互流程。
七、为什么要做“模型配置层”
在接 Kie.ai 之前,我很明确地知道一个问题:不同模型的参数结构是不一样的。
比如当前我接入的三个模型:
- kling/v2-1-master-text-to-video
- wan/2-2-a14b-text-to-video-turbo
- sora-2-pro-text-to-video
它们虽然都属于文生视频,但参数差异很大:
- Kling 支持 duration、aspect_ratio、negative_prompt、cfg_scale
- Wan 支持 resolution、seed、acceleration、enable_prompt_expansion
- Sora 则是 aspect_ratio、n_frames、size、remove_watermark
如果把这些逻辑全都硬编码在页面里,后面只要新增一个模型,前端组件就会越来越乱。
所以我做了一个“模型配置层”,把每个模型的这些信息单独抽出来:
- 模型 id
- 展示名称
- 简介
- prompt 长度限制
- 默认值
- 参数字段定义
- 字段类型
- 字段说明
- 可选项
这样前端就可以根据当前模型动态生成对应的表单,而不是把所有参数逻辑写死在组件里。
这一步非常关键,因为它让项目从“只支持一个模型的 Demo”变成了“可扩展的多模型工作台”。
八、Kie.ai 的接入方式
Kie.ai 的视频生成接口不是同步返回视频结果,而是一个典型的异步任务流:
- 调用 createTask
- 返回 taskId
- 再调用 recordInfo
- 轮询任务状态,直到 success 或 fail
这意味着我们不能像调用普通接口那样“一次请求拿到最终结果”,而必须围绕任务状态来设计前后端交互。
我在这个项目里的处理方式是:
- 前端只调用我自己的 API
- 服务端负责和 Kie.ai 通信
- 服务端创建任务后返回 taskId
- 前端拿到 taskId 后开始轮询自己的查询接口
- 服务端查询 Kie 任务状态并返回统一格式
- 成功时解析 resultJson 中的 resultUrls
- 前端展示视频结果
这种设计有几个明显好处:
- KIE_API_KEY 只存在服务端,不暴露给前端
- 前端不需要知道 Kie 的底层协议细节
- 后续如果更换供应商或加一层任务持久化,前端改动会更小
九、这个项目里最像“工程化”的地方
如果让我挑这个项目里最值得写进博客的“工程化细节”,我会选下面三个。
1. 模型参数校验
虽然前端会根据模型动态渲染参数表单,但真正的参数校验还是放在服务端做。
比如:
- Kling 的 duration 只能是 5 或 10
- Wan 的 seed 必须在范围内
- Sora 的 n_frames 只能是 10 或 15
这意味着即使前端被绕过,服务端也能挡住无效输入。这一点对 AI 接口接入非常重要,否则出错信息会非常难追踪。
2. 统一错误映射
Kie.ai 返回的错误并不一定适合直接展示给用户,所以我在服务端把一些常见状态做了更可读的映射,比如:
- 401:API Key 无效
- 402:余额不足
- 422:模型参数不合法
- 429:请求过频
这样前端可以直接展示更清晰的错误信息,而不是把原始接口报错原样甩给用户。
3. 结果解析
Kie 查询接口返回的 resultJson 本身是一个 JSON 字符串,不是直接可用的对象,所以还需要再 parse 一次,才能拿到最终的视频 URL 列表。
这类细节非常容易在第一次接入时忽略,但真实开发时恰恰是最容易卡住人的地方。
十、这个项目现在还不算“生产级”
如果我要对这个项目做一个诚实评价,我会说:
它已经是一个完整的产品原型,但还不是生产级的 AI SaaS。
原因主要有几个。
1. 任务还没有持久化
当前版本直接把 Kie 的 taskId 当作 generation id 使用,并没有把生成任务存进自己的数据库。
这对原型验证完全够用,但如果想支持:
- 我的历史记录
- 失败重试
- 任务追踪
- 用户资产管理
那就必须把任务表补上。
2. 轮询还在前端完成
现在是前端定时查询任务状态,这很适合 Demo,但正式环境更推荐:
- 服务端持久化任务
- 可选 Kie 回调
- 队列或定时任务处理状态同步
3. 用户系统还比较轻量
当前只支持邮箱密码登录,没有做:
- 邮箱验证
- 找回密码
- 第三方登录
- 用户资料管理
4. 数据库管理方式还很轻
当前用户表是在运行时自动检查和创建的,这对实验项目很方便,但生产环境更适合 migration 驱动。
所以如果我要在博客里描述它,我会把它定义为:
一个非常完整的 AI 视频生成产品原型,而不是最终可直接商用的生产系统。
十一、开发过程中踩过的坑
做这个项目的时候,也遇到了几个很典型的问题。
1. Google Fonts 拉取失败
一开始我用了 next/font/google,结果因为网络环境问题,开发时拉取字体失败。后来改成了项目本地可用的 GeistSans,避免页面依赖外网字体资源。
2. 数据库连接串错误
后面调鉴权的时候,出现过 getaddrinfo ENOTFOUND,最后发现不是代码问题,而是 .env 里的 Supabase Host 写错了,域名被拼坏了。这种问题很隐蔽,但在本地调试时很常见。
3. PowerShell 读取动态路由文件
读取 [taskId] 这样的路径时,PowerShell 会把中括号当模式处理,后来改成 -LiteralPath 才正确读取到文件。
这些坑看起来很小,但对真实开发记录来说,反而很有参考价值。
github源码 : https://github.com/qiuxuezhe345/VibVib-